
- AI 패러다임이 정답을 찾는 '학습'에서 방대한 맥락을 이해하는 '추론'으로 넘어가면서, 데이터를 임시 저장하는 KV 캐시 메모리 수요가 폭증하고 있습니다.
- 이를 해결하기 위해 메모리 데이터를 적은 비트로 압축하는 '터보 퀀트(Turbo Quant)' 기술이 도입되었으나, 정보 손실이라는 근본적인 한계를 동반합니다.
- 다수의 AI 에이전트 구동과 개인화 서비스가 확대될수록 메모리 인프라의 한계는 더욱 시험받을 것이며, 향후 AI의 가치는 '토큰 대비 투자 수익률(ROI)'로 평가될 전망입니다.

여러분, 엔트로픽의 AI '클로드(Claude)'를 아시나요? 이 이름은 현대 정보이론의 창시자인 수학자 '클로드 섀넌(Claude Shannon)'에서 따왔습니다. 왜 최첨단 AI가 1940년대 수학자의 이름을 빌렸을까요? 간단하게 말씀드리자면, 지금 AI 산업이 직면한 가장 거대한 장벽이 바로 클로드 섀넌이 평생을 바쳐 연구했던 '제한된 공간에 정보를 압축해 전달하는 문제'와 똑같기 때문입니다. 현재 AI는 엄청난 양의 메모리를 집어삼키고 있으며, 이를 해결하기 위해 등장한 '터보 퀀트(Turbo Quantization)' 기술은 결국 이 오래된 수학적 원리에 빚을 지고 있습니다.
학습의 시대에서 추론의 시대로: 왜 메모리인가?
우리가 생각하는 것과는 다르게, 지금 AI 산업의 핵심은 '학습'에서 '추론'으로 완전히 넘어가고 있습니다. 제프리 힌튼 교수가 주도했던 학습의 시대에는 인터넷에 흩어진 수많은 데이터를 바탕으로 정답(Y)과의 오차를 줄이는 미분 계산이 핵심이었습니다. 이때는 연산을 빠르게 처리할 GPU가 절대적으로 중요했습니다.
그런데 여기서 중요한 건, 정답(Y)만 맹신하다 보니 AI가 환각 현상(Hallucination), 즉 거짓말을 지어내는 문제가 발생했다는 점입니다. 이를 해결하기 위한 추론의 시대에는 접근법이 다릅니다. AI에게 미리 방대한 양의 정확한 맥락 데이터(X)를 왕창 넣어주고 그 안에서 답을 찾게 만드는 것입니다. 사용자의 과거 대화 기록, 개인 문서, 이메일, 위치 정보까지 수백만 개의 텍스트가 프롬프트의 배경 지식으로 깔리게 됩니다.

학습과 추론의 수학적 차이를 설명하는 슬라이드와 대담 장면
이해를 하셔야 됩니다. 이 수많은 맥락 데이터는 AI가 작동하는 동안 'KV 캐시(Key-Value Cache)'라는 형태로 메모리에 계속 저장되어 있어야 합니다. 연산 능력이 아무리 뛰어나도, 이 거대한 데이터를 담아둘 공간이 없다면 AI는 제대로 된 추론을 할 수 없습니다. 과거에는 미분 연산이 중요했다면, 이제는 데이터를 쥐고 있을 메모리의 크기가 AI의 성능을 좌우하는 시대가 된 것입니다.
AI의 숨겨진 메모리 폭식: 내부 경쟁과 '오토드림'
그렇다면 AI는 도대체 메모리를 얼마나 쓰고 있을까요? 사실은 우리가 상상하는 것 이상으로 엄청나게 소모하고 있습니다. 최근 유출된 AI 코드들을 분석해 보면 의아했던 점들이 풀립니다.
우리가 AI에게 "보고서 하나 써줘"라고 명령을 내리면, 내부에서는 AI 에이전트 하나만 일하는 것이 아닙니다. 퀄리티를 높이기 위해 두세 개의 에이전트가 동시에 각기 다른 버전의 글을 쓰고, 또 다른 평가 AI가 이를 심사하여 가장 좋은 결과물을 우리에게 보여줍니다. 기업 내부에서 여러 팀이 경쟁 PT를 하는 것과 같은 원리입니다. 결과적으로 우리가 프롬프트 한 줄을 입력할 때 AI는 내부적으로 3배 이상의 메모리를 사용하게 됩니다.
또 하나 재밌는 건, AI도 사람처럼 '꿈'을 꾼다는 사실입니다. 사용자가 AI를 쓰지 않고 켜두기만 해도, AI는 언제 들어올지 모르는 질문에 대비해 앞선 대화의 맥락을 메모리에 쥐고 상시 대기합니다. 그러다 12시간 정도가 지나면 메모리를 재정리하며 장기 기억으로 넘길 것과 지울 것을 분류하는 이른바 '오토드림(Auto-dream)' 작업을 수행합니다. 이 과정에서 메모리 사용량은 에어컨 틀 때의 전력 피크처럼 치솟게 됩니다. 이런 요인들이 겹치며 메모리 수요는 그야말로 폭증하고 있습니다.
터보 퀀트의 등장: 메모리를 압축하는 수학적 마법
자, 그래서 등장한 구원투수가 바로 '터보 퀀트'입니다. 하드웨어적으로 메모리를 무한정 늘릴 수는 없으니, 소프트웨어와 수학의 힘을 빌려 메모리 용량을 압축하자는 시도입니다.
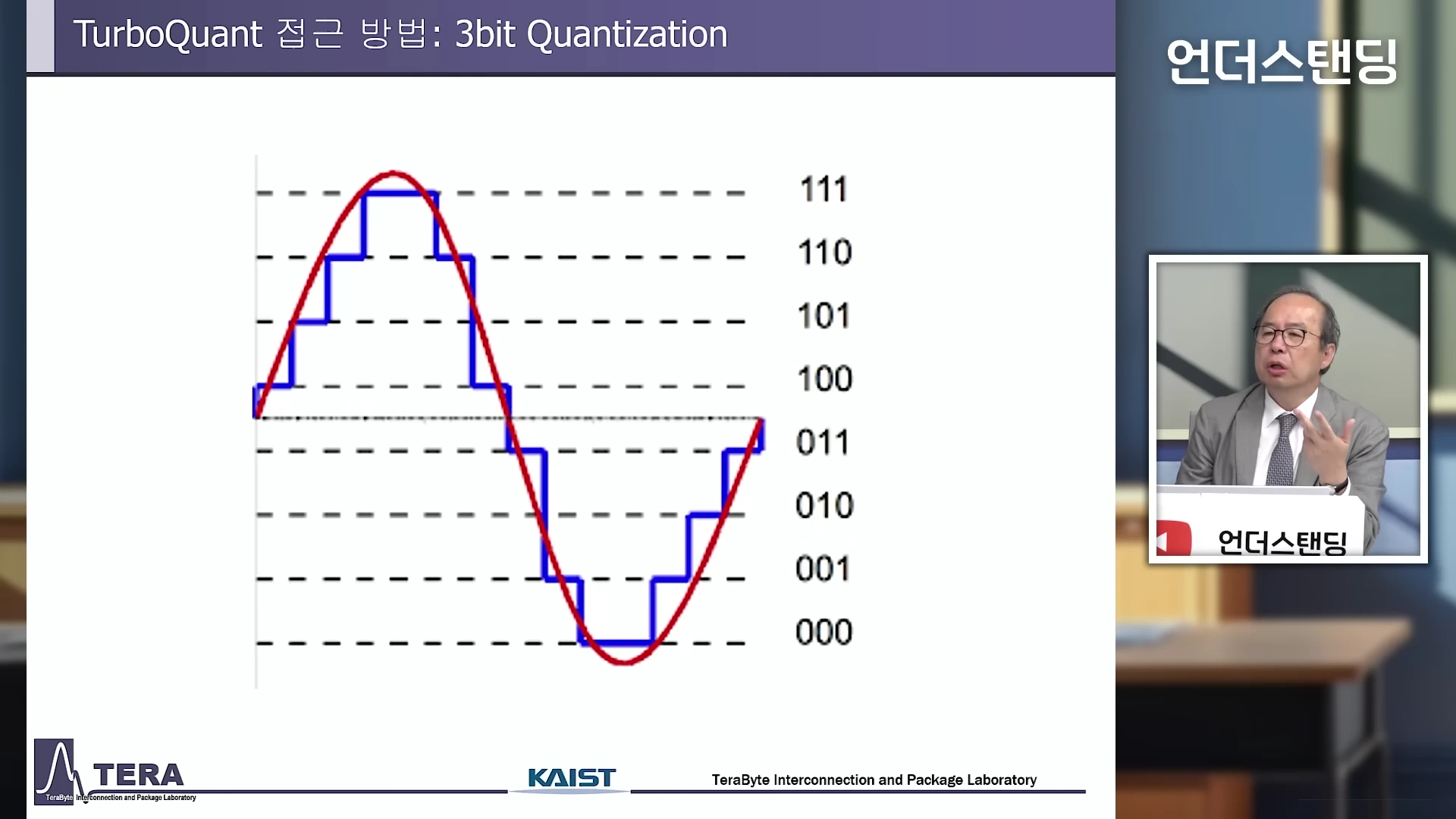
3비트 양자화 원리를 설명하는 그래프와 강연하는 김정호 교수
KV 캐시를 저장할 때, 기존에는 하나의 숫자를 표현하기 위해 32비트나 16비트의 넉넉한 공간을 썼습니다. 터보 퀀트는 이를 8비트, 심지어 3비트 수준으로 확 줄여버립니다. 소수점 아래 길고 복잡한 숫자들을 과감히 쳐내고, 아주 단순한 단위로만 데이터를 저장하는 것입니다. 이렇게 비트 수를 줄이면 메모리 사용량은 획기적으로 감소합니다. 클로드 섀넌이 제한된 통신 채널에서 노이즈를 줄이고 데이터를 압축해 보내려 했던 그 수학적 원리가, 오늘날 부족한 AI 메모리 환경에서 그대로 재현되고 있는 셈입니다.
공짜 점심은 없다: 정보 손실과 인프라의 미래
하지만 세상에 공짜 점심은 없습니다. 메모리를 줄이는 대가는 분명히 존재합니다. 복잡한 데이터를 3비트로 압축한다는 건, 비유하자면 우리가 하고 싶은 모든 말을 오직 '3음절'로만 표현해야 하는 것과 같습니다. "밥 먹자", "자러 가"처럼 기본적인 의사소통은 가능하겠지만, 미묘한 감정 표현이나 정교한 뉘앙스는 모두 날아가 버립니다. 메모리를 아낄 수는 있어도, 섬세한 표현력과 정확도라는 정보의 손실은 피할 수 없는 한계입니다.
결국은 하드웨어 인프라가 뒷받침되어야 합니다. 개인화된 AI 에이전트가 24시간 우리를 대신해 일하는 시대가 오면, 데이터센터의 90%가 메모리로 꽉 채워질지도 모릅니다. 디램(DRAM)만으로는 감당할 수 없어 낸드플래시나 하드디스크까지 동원해 장기 기억을 불러오는 시간차를 줄여야 할 것입니다.
애플 같은 기업에서는 이미 직원들이 '토큰을 얼마나 썼는지'로 업무 기여도를 평가한다고 합니다. 머지않아 AI 시장의 핵심 화두는 "그래서 그 비싼 토큰과 메모리를 써서 얼마의 가치(ROI)를 만들어냈는가?"로 이동할 것입니다. 터보 퀀트는 이 거대한 메모리 비용의 압박 속에서 시간을 벌어주는 임시방편일 뿐, AI 산업이 넘어야 할 '메모리 병목'이라는 산은 이제 막 그 거대한 모습을 드러냈습니다.
FAQ
터보 퀀트(Turbo Quantization) 기술이 무엇인가요?
AI가 문맥을 기억하기 위해 사용하는 'KV 캐시' 데이터를 적은 비트(예: 8비트, 3비트)로 압축하여 메모리 사용량을 획기적으로 줄이는 기술입니다.
왜 갑자기 AI에서 GPU보다 메모리가 중요해졌나요?
AI가 정답을 학습하는 단계를 넘어, 사용자의 개인 문서나 대화 기록 등 방대한 맥락(Context)을 입력받아 추론하는 시대로 진입했기 때문입니다. 이 거대한 맥락을 유지하려면 엄청난 메모리 공간이 필수적입니다.
AI 메모리를 터보 퀀트로 압축하면 부작용은 없나요?
'공짜 점심은 없다'는 말처럼, 비트 수를 줄여 압축하면 미세한 감정 표현이나 정교한 뉘앙스를 잃어버리는 정보 손실이 발생할 수밖에 없습니다.
